Working with an In-House Programming Language
In the company I’m currently working for, Senior Sistemas, they have an in-house, proprietary programming language called LSP (Senior Programming Language). It’s an imperative programming language, based on Delphi, created on Delphi and Java, and with Portuguese syntax. For more information, here’s the documentation.
So when I started to work at Senior and people presented me this weird language, what bothered me the most was the lack of productivity while coding in it. Mostly because the only way to code in LSP is either using an ordinary text editor, missing any auto-complete functionality and even code highlighting, or using the in-house semi-IDE from the image below:
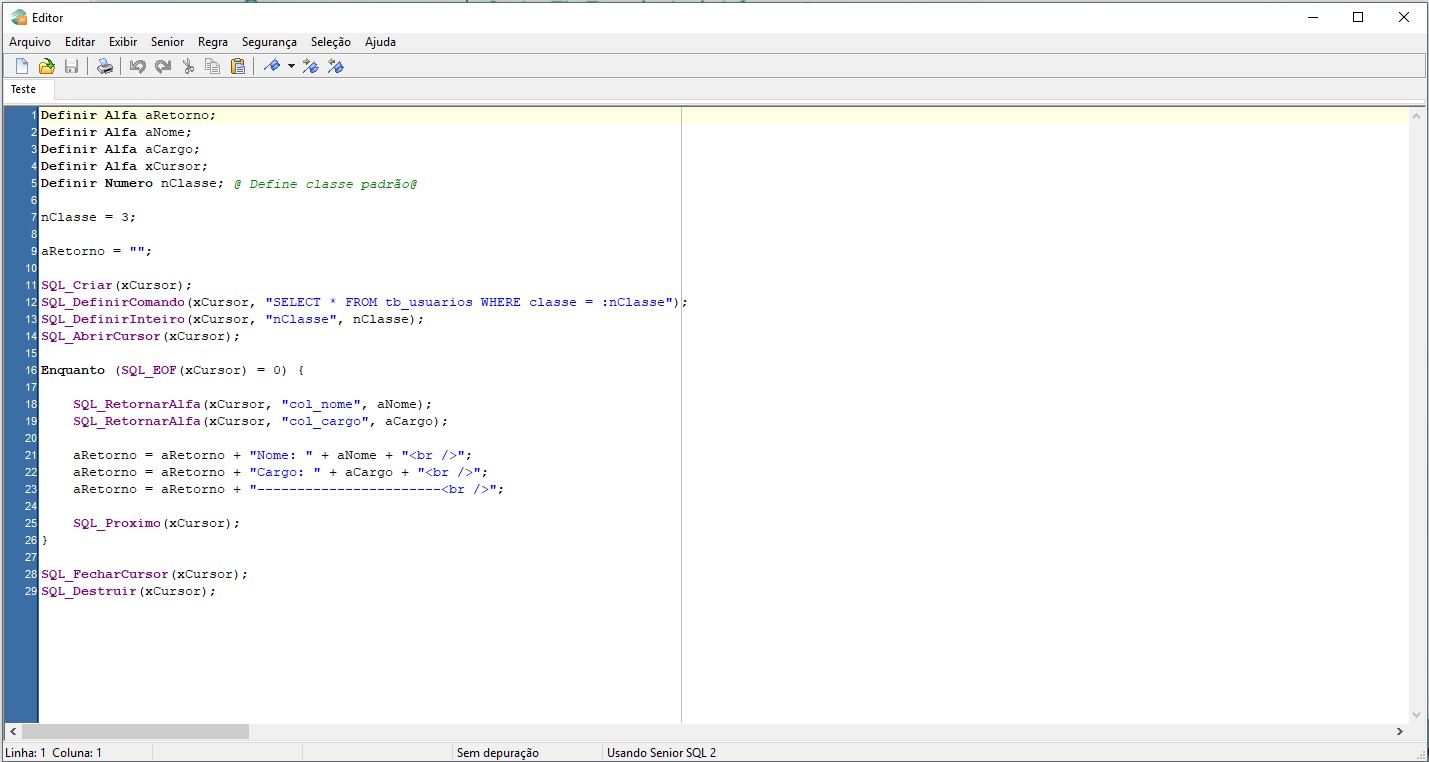
Needless to say, it was an awful beginning. So I came up with a plan to create some Atom packages to support LSP, namely, a code highlighter and a simple linter.
Code highlighter
Highlighting LSP code for Atom was pretty straightforward. I just had to follow some tutorials and simple steps, such as the official documentation.
Based on that, I highlighted most of LSP reserved keywords and its syntax, like:
- Comments
patterns: [ { begin: '@' end: '@\\s*\\n' name: 'comment.line.character.lsp' } { begin: '/\\*' beginCaptures: '0': name: 'punctuation.definition.comment.begin.lsp' end: '\\*/' endCaptures: '0': name: 'punctuation.definition.comment.end.lsp' name: 'comment.block.lsp' } ] - Numbers
patterns: [ { match: '\\b(([0-9]+\\.?[0-9]*)|(\\.[0-9]+))((E|e)(\\+|-)?[0-9]+)?\\b' name: 'constant.numeric.lsp' } ] - Strings
patterns: [ { begin: '"' beginCaptures: '0': name: 'punctuation.definition.string.begin.lsp' end: '"' endCaptures: '0': name: 'punctuation.definition.string.end.lsp' name: 'string.quoted.double.lsp' patterns: [ { match: '(\\\\"|\\\\\\\\)' name: 'constant.character.escape.lsp' } ] } ]
The complete highlighter can be found here.
Linter
Now, creating a LSP linter was a more difficult beast.
Looking at how a linter is made, I would need the language’s compiler, or at least a grammar specification, usually in Backus-Naur form. But LSP doesn’t have an easy-to-get compiler, and nobody with whom I spoke knew where I could get it. And for the BNF, well, let’s just say that’s not the path they chose when creating the language.
Luckily for me, I took a compilers course in my undergrad school, so I devised a way to create a BNF grammar based on samples from LSP that I could get my hands on, i.e., I reverse engineered the language’s syntax and created a grammar for it. For each snippet of LSP that I encountered, I would run my most updated compiler on it, and correct it accordingly. Rinse and repeat. Until at some point I had a pretty good grammar/compiler that would accept every valid testing snippet I had, and reject every invalid snippet I created.
Using Jison, a JavaScript version of the famous Bison parser generator, I used my LSP’s grammar to create a parser of the language, which I added to an Atom package to compose the final LSP’s linter.
My version of the LSP’s grammar is totally incomplete, and even fails in simple cases, the saddest one being negative numbers: the grammar doesn’t recognize -1 as a valid number, only something as ugly as 0 - 1.
But my grammar and its parser have validations for special LSP cases, which really helped boost my productivity in such an unproductive language. Most of these validations have to do with undeclared variables and SQL cursor functions and their orders.
Example
When running a SQL query in LSP, one needs to call lots of cursor functions, like the following example:
SQL_Criar(curGetIDs);
SQL_DefinirComando(curGetIDs, "SELECT id FROM some_table WHERE id > :param");
SQL_DefinirInteiro(curGetIDs, "param", 10);
SQL_AbrirCursor(curGetIDs);
Enquanto (SQL_EOF(curGetIDs) = 0) {
}
SQL_FecharCursor(curGetIDs);
SQL_Destruir(curGetIDs);
Often, programmers would invert the order of the SQL_DefinirInteiro and SQL_AbrirCursor functions, so the query parameters wouldn’t be filled and the results returned would seem wrong, and they’d spend hours searching for a bug in the query itself or in the client’s database.
The following snippet defines the order in which such functions must be called (prioridade is Portuguese for priority):
var ordemFuncoesCursoresAvancados = [
{funcao: 'sql_criar', prioridade: 1},
{funcao: 'sql_usarsqlsenior2', prioridade: 2},
{funcao: 'sql_usarabrangencia', prioridade: 2},
{funcao: 'sql_definircomando', prioridade: 3},
{funcao: 'sql_definir', prioridade: 4},
{funcao: 'sql_abrircursor', prioridade: 5},
{funcao: 'sql_retornar', prioridade: 7},
{funcao: 'sql_proximo', prioridade: 8},
{funcao: 'sql_fecharcursor', prioridade: 9},
{funcao: 'sql_destruir', prioridade: 10},
];
And then the function cursoresAvancadosEmOrdem() in my grammar checks for such an order in the source code.